
The notion of a domain was first introduced into alignment syntax in Miklós Gáspár’s PhD dissertation (2005) as a device to allow precedence and subsequence relations to hold over more than two elements. It has proved extremely useful in the framework and although there has been substantial development to the notion (especially in Newson & Maunula 2006) its main purpose remains as Gáspár first envisioned. His intuition was that a wh-element, for example, does not just precede (albeit at a distance) its predicate, but that it precedes all the elements that it has scope over. Therefore with the aid of an interrogative domain, we can define a constraint which places the wh-element as its first element:☞For convenience we will make use of the following conventions in defining constraints. First we will give the constraint name, which consists of three parts: the target, i.e., that which is positioned by the constraint; the relation, which is the type of alignment which holds of the target (precedence, represented as p, subsequence, represented as f or adjacency, represented as a), and the host, which is what the target is aligned to and may be a single element or a domain. Domains are indicated as DX, where X identifies the nature of the domain. The second item in the definition of the constraint is a description of the constraint name, given for clarification purposes. The last item provides the violation conditions of the constraint and as such provides its definition.
| [WH]pDWH | the wh-element precedes interrogative domain |
| violated by every member of DWH which | |
| precedes WH |
Of course, this is exactly what a structural account does: a wh-element is at the front of the structural unit (the interrogative clause) that it has scope over, so the domains approach is not particularly novel. But this similarity in the uses of domains and structural units may lead to the sneaking suspicion that the two are identical and that domain is just another name for phrase, smuggled into a theory which is supposed to operate with linear rather than constituent structural notions.
It is the intention of the present paper to argue that the domain and structural approaches are very different and that one cannot be seen as just a notational variant of the other. The main thrust of this argument will be based on an analysis of the basic arrangement of clausal elements in English and German. This analysis not only leans heavily on the notion of domains, but in doing so provides a novel view of the organisation of clausal elements which has many properties which are substantially different from the standard phrase structure based approach. Problems and their solutions are discussed which have not, and probably could not have, arisen from the perspective of a structural organisation.
The paper is organised into seven sections. After this introduction, some superficial similarities between clause structures and domains are discussed. This serves to introduce the domains we will be basing our analysis on as well as to juxtapose the two approaches so as to highlight their differences. The following four sections detail the analysis, starting with the details of the internal organisation of the inflection and argument domains. This continues with sections which detail how the domains relate to each other and the “linchpin” function of the root. This ends with a detailed discussion and analysis of the organisational differences in German matrix and subordinate clauses and the role of the complementiser. The final section discusses possible extension of the approach to wh-phenomena, though a full analysis is not developed here. The purpose of the discussion is again to highlight differences in the structural and domain based approaches. It will be seen that although both are applicable to the same range of phenomena, they address it in very different ways.
Ever since the introduction of the VP Internal Subject hypothesis (Koopman & Sportiche 1991) it has been possible to view the sentence as being organised into discrete parts, each of which has to do with distinct syntactic/semantic aspects of the sentence. The lower part, essentially the VP, has to do with thematic elements (the predicate and its arguments) and their arrangement. On top of this we have the functional structure associated with tense, modality and aspect — essentially the IP and whatever functional structure lies between the inflection and the VP. A version of this idea is depicted in (2).

The individual elements within each part of the structure are ordered by a number of principles including subcategorisation specifications of the heads☞For example, the inflection subcategorises for a verbal complement and so the perfect will follow tense rather than the other way round. and independent ordering specifications.☞Such as the theta hierarchy which determines the order of the arguments in the VP. See Larson (1988) for a suggestion along these lines. This order is subject to change by processes which serve to mingle the elements of both parts of the structure. The subject moves out of its VP internal position to the specifier of the IP, preceding all elements of the functional section of the clause, and the verb may move up into the functional elements (or some functional element may move down to the verb — depending on one’s theoretical stand point). Hence we end up with something which looks like the following:
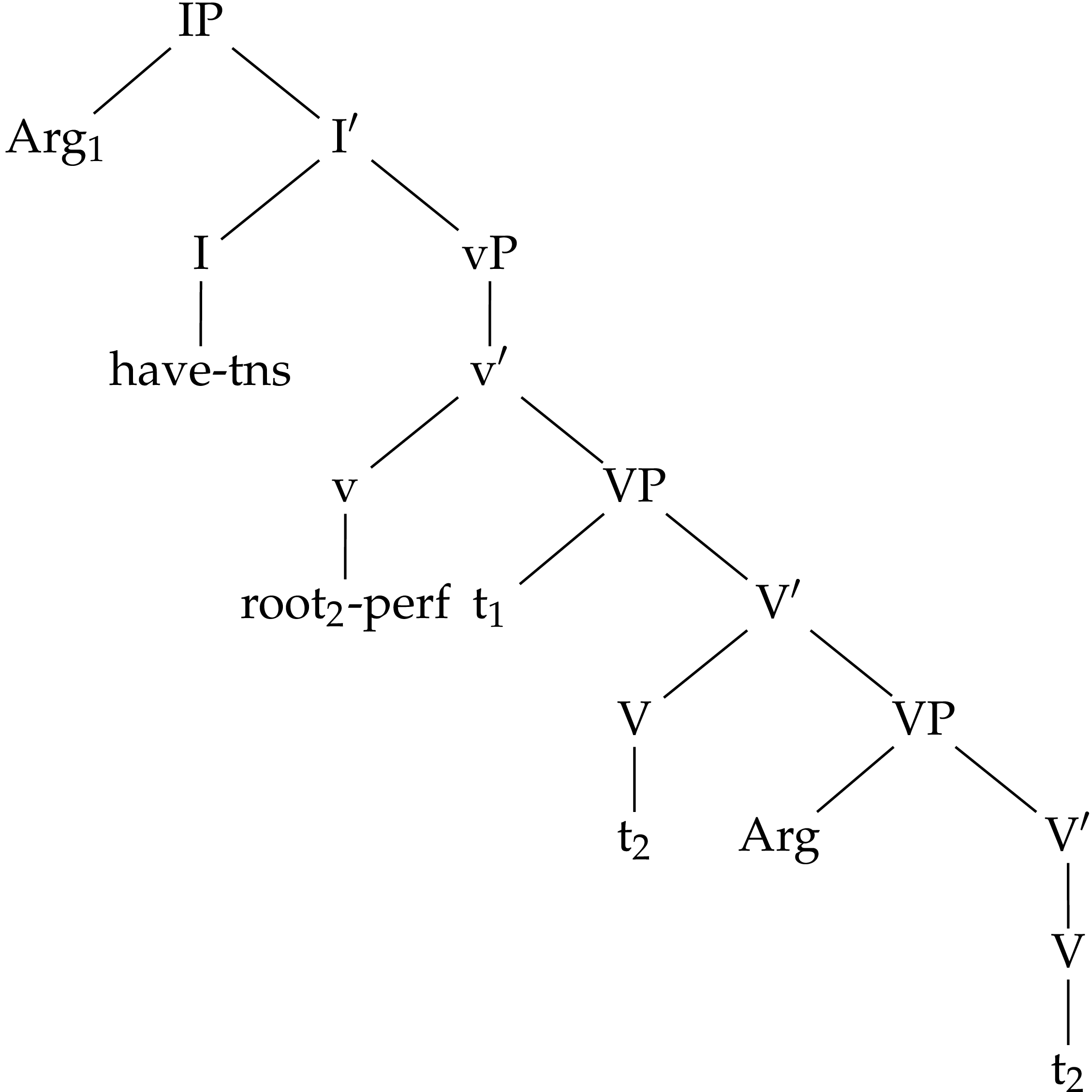
We can envisage a similar analysis to this in a linear approach, making use of domains to replace the structures discussed above. For example, parallel to the notion of the VP, we might conceive of an argument domain, made up of all of the arguments associated with a predicate. The IP might be related to an inflection domain, made up of all the functional elements (modal, tense and aspectual) which modify the predicate. However, while these domains bear obvious similarities to the relevant phrases, they are quite unlike them in nature. We can best see this in terms of how the elements of each domain are organised with respect to the domain. It is important to understand how domain based alignments work in order to see this difference. Such constraints are violated by members of the domain which are not in the relevant relation to the target. Crucially, they are not violated by any element which is not a member of the domain. This fact means that domain based constraints are evaluated as though only the members of the domain are present: all other elements are simply ignored. Of course, the domains do not exist independently of all the other input elements and candidates are orderings of all input elements. However, this property of domain based constraints allows us to consider domains as though they do have independent existence. A brief example might help to clarify. Suppose we have a domain consisting of two elements a and b. These are included in an input along with another element x which is not a member of this domain. Further suppose two constraints relating to this domain, one which wants a to precede the domain and the other that wants b to precede it.☞A member of a domain can precede that domain if no member of the domain precedes it. Recall that the definition of a constraint is given by its violation conditions and a domain precedence constraint is violated by every member of the domain that precedes the target. Given that an element cannot precede itself, a domain precedence constraint will be perfectly satisfied if no other member of the domain precedes the target. This puts a and b into competition with each other as to which should come first and the outcome of the competition will be decided by the ranking of these constraints. Note, however, that as far as this competition is concerned, it does not matter where x is placed with respect to a and b:
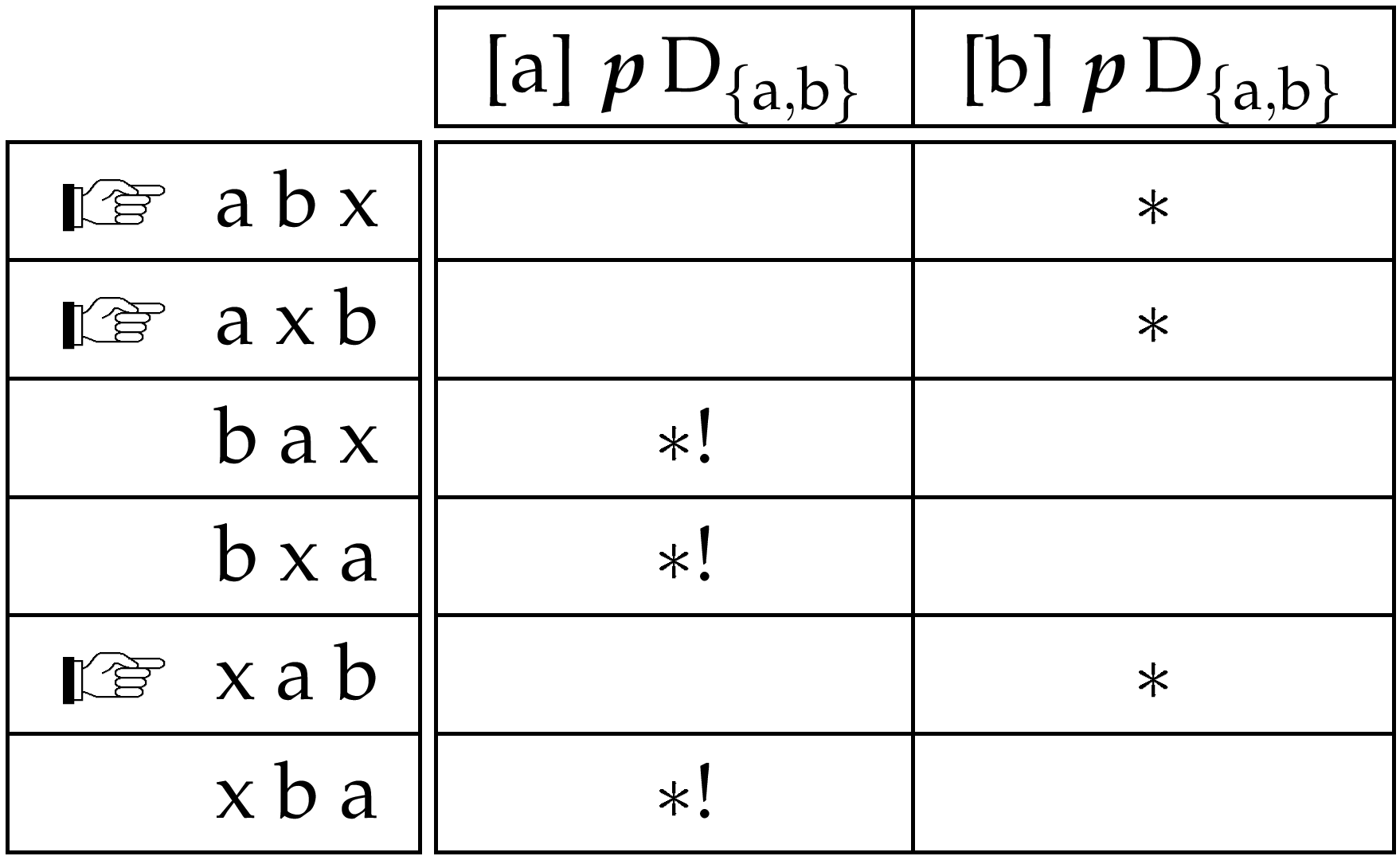
There will be other constraints relevant for the positioning of x, but the point is that as far as the organisation of the domain members is concerned, we might as well ignore this element and the competition in effect reduces to the following:
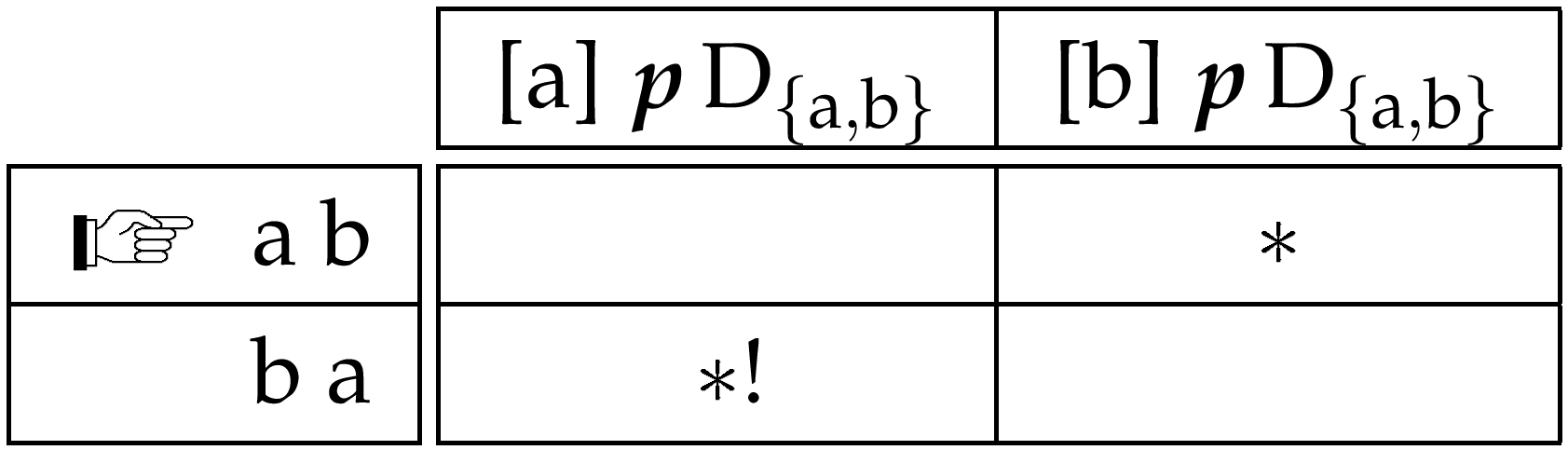
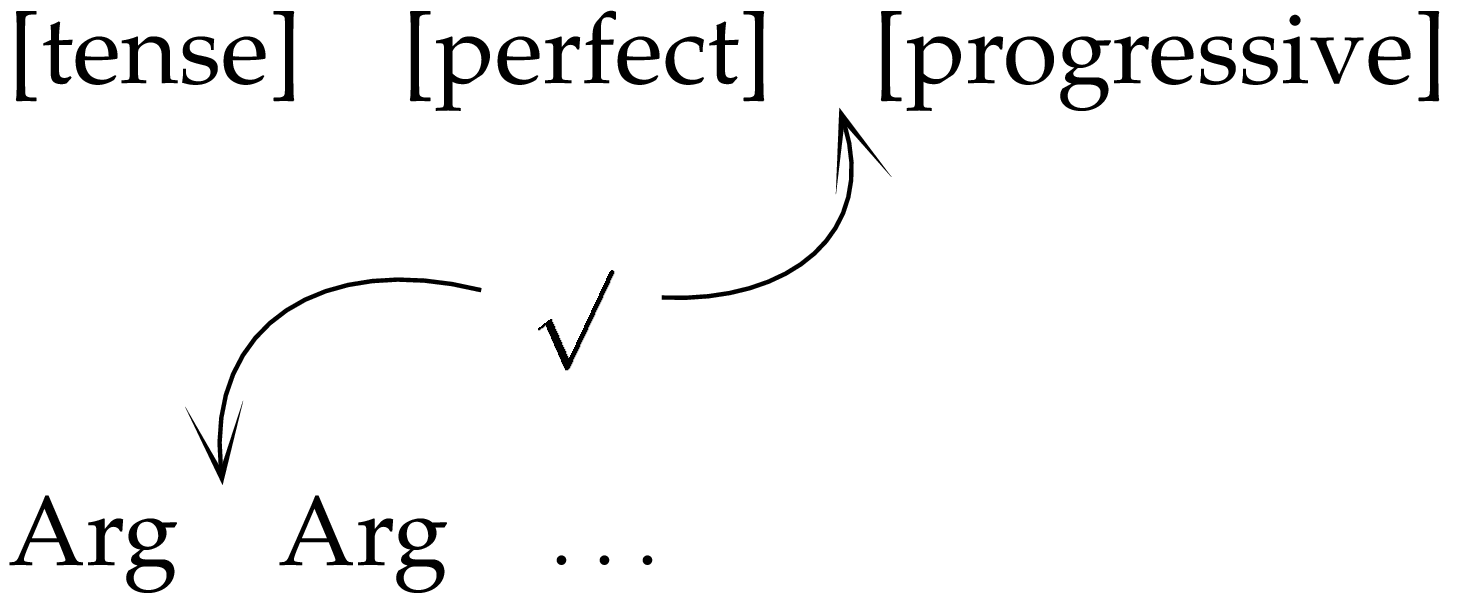
Turning now to the cases of the argument and inflection domains, we see that these are organised similarly to the above simplified case. Each inflectional element competes with the others to be first in the domain, with tense, when present, preceding perfect, when present and progressive, when present. Perfect, in turn, precedes progressive. We can represent this in the following way:
| [tense] | [perfect] | [progressive] |
The argument domain is similarly organised with each argument in competition with the others to precede the domain:
| Arg | Arg | … |
These domains do not exist independently of each other in the linear string, but the ordering principles to which they are subject only consider them in isolation. However, there is interaction between the elements of both domains. This is primarily accomplished by the root, which is not a member of either domain, but is positioned with respect to both. As demonstrated in Newson (2010), the root is positioned in the second to last position within the inflection domain, always being followed by one of its members:
| √ [tense] | play-ed |
| [tense] √ [perfect] | had see-n |
| [tense] [perfect] √ [progressive] | had be-en run-ing |
It is also a fairly straightforward observation that the root is positioned after the first element of the argument domain as the verb always follows the subject but typically precedes other arguments:
| Arg √ | John swam |
| Arg √ Arg | John saw Bill |
| Arg √ Arg Arg | John sent Fred a letter |
These requirements for the positioning of the verb necessarily entail that there will be some intermingling of the inflection and argument domains. We might envisage this in the following way, though it is important to bear in mind that ordering is determined in the single linear string and that at no derivational point in the process are the domains actually separated like this:
Due to other alignment conditions, which we will elaborate on a little later, the end result of this interaction will be:
| Arg | [tense] | [perfect] | √ | [progressive] | Arg | |
| John | had | be | -en | watch | -ing | TV |
The point of juxtaposing these two approaches is to point out that although there seem to be a number of similarities between them, there are also some rather large differences which make it difficult to sustain the claim that one is a notational variant of the other. For example, while both approaches identify similar elements belonging to the relevant sub-areas of the sentence, they are not identical. Specifically the phrase-based approach necessarily has the root as being part of the sub-structure containing the arguments, as it is ultimately the head of this structure. It would not make much sense from this perspective to consider the set of arguments as forming a phrase independently of the root, and to my knowledge no one has ever considered such a thing. It is easy to see why. Thematic relations which hold between a predicate and its arguments are established syntactically in the lower substructure, the assumption being that this arrangement feeds the interpretation component and the arguments are interpreted with respect to the predicate based on their position within this.☞Other assumptions might not lead to the same conclusion. For example, in LFG argument-predicate relations are established in a non-constituent structure arrangement. Thus it would be possible to arrange things so that the arguments form a constituent separate from the root, though again, to my knowledge, this has never been proposed.
From the domain based approach, however, there is nothing wrong with taking the set of arguments as forming a domain as no inconsistencies follow from this. The semantic relations are formed in the input and interpreted from this. So nothing is lost by conceiving of a domain of arguments without the predicate. Domains, not being interpreted themselves, therefore have only syntactic significance, though they may be based on the semantic relations established in the input. There is substantial evidence that the organisation of inflection and argument domains are largely independent of each other and, largely independent of the position of the root. For example, we can often observe changes in one domain which have no effect on the other. We can also observe changes to the position of the root which have no effect on the organisation of the domains themselves. In English, the argument domain can undergo a change which involves one of its members occupying a different position with respect to the other arguments, though this has no effect on the organisation of the inflection domain, or indeed on the position of the root. One such example concerns topicalisation:
| a. | Arg1 | [tense] | √ [perf] | Arg2 | Arg3 |
| John | has | given | Barry | the bill |
| b. | Arg3Top | Arg1 | [tense] | √ [perf] | Arg2 |
| the bill, | John | has | given | Barry |
Note that the inflection domain and the position of the root within it are unaffected by this rearrangement of the arguments.
An even more dramatic effect can be seen in German where the inflection domain is affected by whether the clause is main or embedded and yet the argument domain remains unaffected by these changes:
| a. | Arg1 | [tense] | Arg2 | Arg3 | √ [perf] |
| Peter | hat | dem Studenten | das Buch | gegeben | |
| Peter | has | the students | the book | given |
| b. | … | Arg1 | Arg2 | Arg3 | √ [perf] | [tense] |
| weil | Peter | dem Studenten | das Buch | gegeben | hat | |
| because | Peter | the students | the book | given | has |
With a simple tense, the effect is more extreme as the root is dragged about by the tense from second to last position, yet the argument domain is unaffected:
| a. | Arg1 | √ [tense] | Arg2 | Arg3 |
| Peter | gab | dem Studenten | das Buch | |
| Peter | gave | the students | the book |
| b. | … | Arg1 | Arg2 | Arg3 | √ [tense] |
| weil | Peter | dem Studenten | das Buch | gab | |
| because | Peter | the students | the book | gave |
Despite all this variation in the inflection domain and the position of the root, the argument domain remains unaffected.
A second difference between the structural approach and the domain-based approach concerns the relationship between the two parts of the sentence. From the structural point of view, this relationship is necessarily one of subordination: the thematic part of the sentence is subordinate to the functional part. This is unavoidable as together both parts must form a single structure so one must be included inside the other. This entails two further properties of the system. Firstly that the thematic part, being the subordinate one, must be a phrase and secondly that any intermingling of the two parts that we observe must result from extra processes, such as movement. These two points are clearly related: if the thematic part of the sentence were not to be seen as a structural unit it could, in principle, be distributed amongst the functional elements by whatever principles establish order within a structure. In practice, however, it is difficult to think how by subcategorisation alone we could account for the ordering of thematic elements within the functional elements. A theory which establishes thematic relations within a single constituent and then moves elements around is therefore a more obvious one.
Within the domain based approach however, this fracturing of the syntactic system is completely unnecessary. This is so because domains are not structural units which have to be manipulated by the grammatical system. Hence it is not necessary to make one domain be subordinate to any other in order to establish a single linear ordering. All that is necessary is for input elements to be ordered with respect to certain other input elements and a single ordering of all the elements can be established without reference to where each element stands with respect to all other elements or how groups of elements stand with respect to others. From this perspective the intermingling of elements of different domains is a natural part of the ordering process.
These observations are made not with the idea in mind to favour one view over the other. It is clear that both approaches can account for the observed phenomena and there is little empirically to separate them. Therefore to favour one view over the other requires arguments of a more subtle kind, concerning which mechanisms are better for other reasons than accounting for observations. Such arguments notoriously tend to be inconclusive and ultimately reduce to personal preferences, which obviously should not be part of scientific argumentation. Until we understand more about the capabilities and limitations of these systems, it is therefore better to avoid such debates.
The real point of these observations is to argue that the domain based approach offers a real alternative to the structure base one. The domain based approach offers descriptions of linguistic phenomena which are impossible to even model using structure precisely because their nature is completely different: a domain is not a phrase and it does not have the same properties that phrases do. Phrases are manipulated by phrase structure grammars and therefore have distributions determined directly by the rules of these grammars. Domains are not themselves manipulated by alignment rules: their members are. Thus if a domain has a distribution that can be observed in data, this is entirely epiphenomenal.
In the next sections we will expand on the domain based analysis overviewed in this section to show how it works, what predictions it makes and the problems it has to overcome. We will start with the constraints which pertain to the individual domains and then move on to the root constraints which determine the interaction between the inflection and argument domains.
The constraints needed to order the inflection domain are the most straightforward, therefore we will deal with those first. For English it is particularly straightforward as the order of the inflectional elements does not alter under any circumstance. We therefore conclude that these constraints are highly ranked with respect to others.
We have already seen that the inflectional elements cannot be seen as aligning to a particular element, such as the root, as their order is unaffected by the conditions on root placement. Moreover, although tense is often present while the other inflectional elements are optional, even tense is not necessary in all situations; for example in Small Clauses. The absence or presence of any particular inflectional CU has very little affect on the ordering of the others however, as detailed below:
| he smiled | [tense] |
| he had seen me | [tense] [perfect] |
| he was running | [tense] [progressive] |
| he had been thinking | [tense] [perfect] [progressive] |
| he was known | [tense] [passive] |
| he had been followed | [tense] [perfect] [passive] |
| he was being shown round | [tense] [progressive] [passive] |
| he had been being beaten | [tense] [perfect] [progressive] [passive] |
| (I watched) him writing | [progressive] |
| (I saw) the window broken | [passive] |
| (I heard) the door being opened | [progressive] [passive] |
In general the situation can be described as follows:
Thus, tense, when present, precedes all other inflectional conceptual units (CUs); perfect, when present, precedes all other inflectional CU, except tense; etc.☞Newson and Szecsényi (2012) argue that a degree inflectional CU, following all others, is necessary to account for predicate adjective constructions.
The fact that there is no single element to which all inflectional elements are aligned indicates that they are aligned to a domain. Their behaviour can be modelled exactly by the following kind of constraint:
| [CUI]pDI | inflectional CU precedes inflection domain |
| violated by every member of DI which precedes [CUI] |
A constraint of this form for each of the members of the domain and a ranking in accordance with (16) will give us exactly the order required, as demonstrated below:
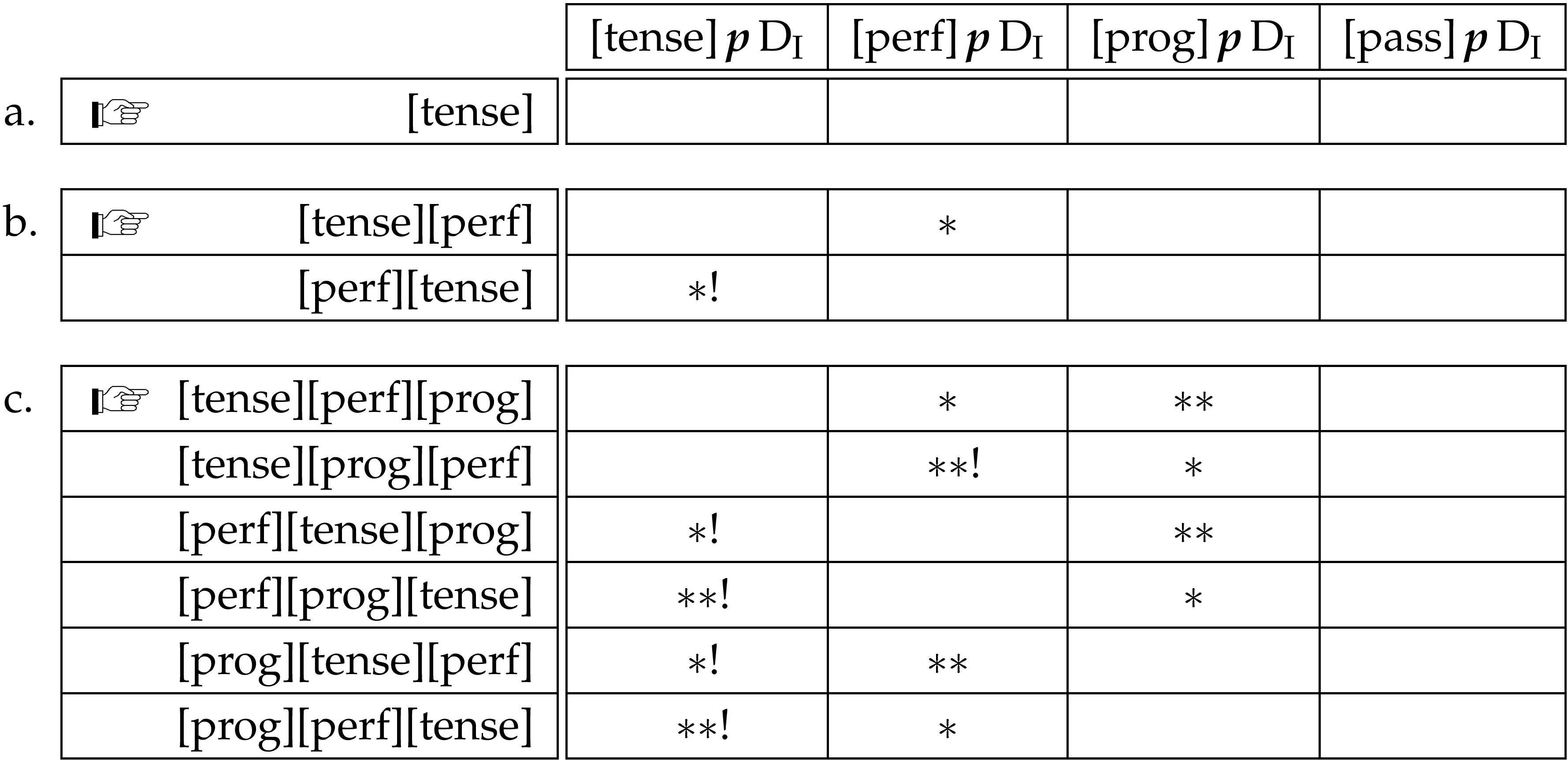
The table in (18) shows the results of three competitions. In (18a) only tense is present, and hence there is only one ordering possible. In (18b) tense and perfect are present and the winning candidate has tense preceding perfect. In (18c) there are three members of the domain present, and so more competitors. The evaluation is the same however, and tense is placed first, perfect second and progressive third.
Note that these results will hold no matter how many other elements from other domains are present or what their positions are with respect to the inflectional CUs as domain based constraints evaluate only the order of the domain members and are effectively blind to the presence of other elements. For this reason, the table in (18) represents a real situation despite the fact that it considers inflectional elements out of context. If the context were to be added, exactly the same results would hold.
If we turn our attention to the German inflection domain, we find that things are a little complicated by the differences between matrix and subordinate clauses, a complication which does not arise in English declaratives. We will take a fairly standard position on this and assume that the embedded situation in the basic one and that the order of inflections in the matrix is subject to special considerations, to which we return. In non-matrix contexts the order of inflections is exactly the opposite to those of English:☞The auxiliary system of German also differs from that of English, having split perfect and passive systems. We will not let the details of these detain us as they are only tangential to the issue at hand.
| weil | der Brief | geschrieben | worden | ist |
| because | the letter | write-[pass] | become-[perf] | be-[tense] |
| ‘because the letter has been written’ | ||||
Clearly we can capture this order easily enough with a different ranking of the constraints in (18). However, it is interesting that the order is not just different to the English one, but its mirror image. This might indicate a certain universality in the inflection system and therefore that there are limits on the ranking of the constraints. The easiest way to capture this is to maintain the same ranking of the inflection domain constraints but assume that it is subsequence rather than precedence which is important in German. We therefore consider a second type of constraint:
| [CUI]fDI | inflectional CU follows inflection domain |
| violated by every member of DI which follows [CUI] |
In order to capture the German data, exactly the same ranking of the inflection domain subsequence constraints is needed as that for inflection domain precedence, as demonstrated below:☞German has no morphological progressive, so we omit the relevant constraint from the table here. It is an interesting question, however, of what we are to say about the treatment of the [progressive] CU in the language as, presumably, functional CUs are universal. In the interests of keeping this discussion within reasonable bounds we will not veer off down this road, but leave it to be explored at some other time.
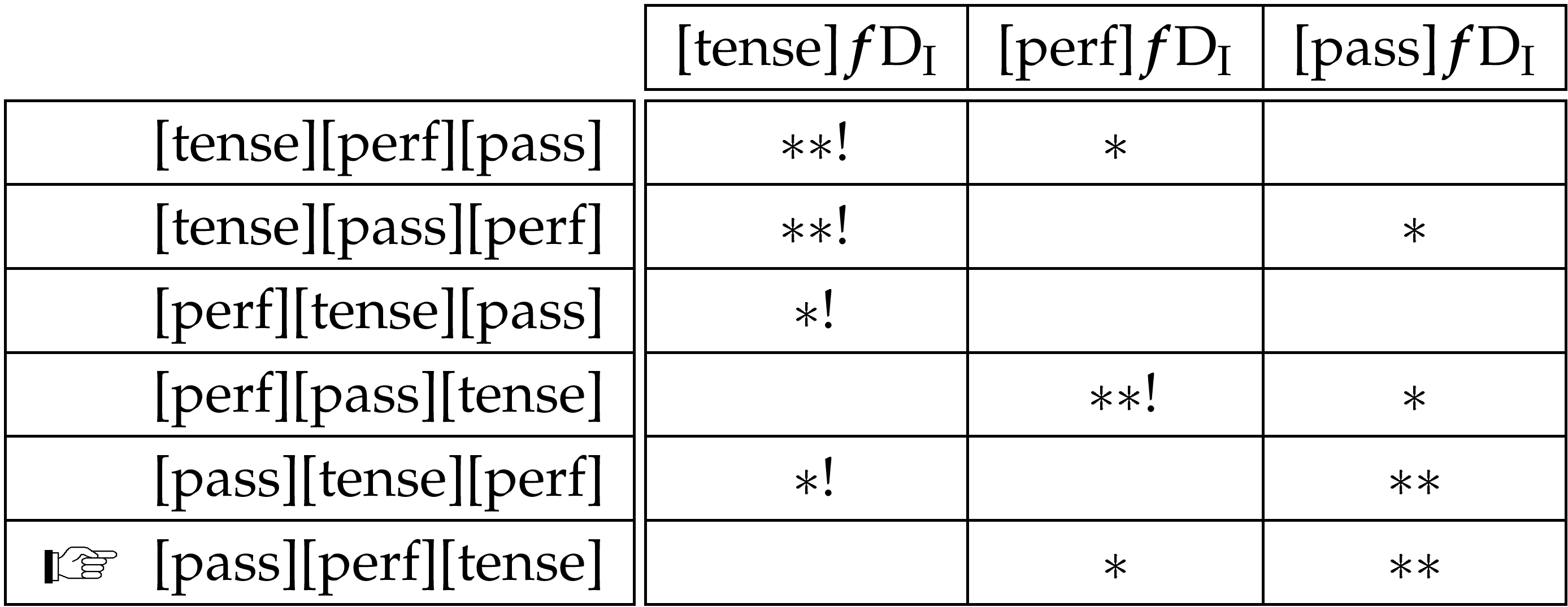
The difference between German and English concerns the relative ranking of the precedence and subsequence constraints. For English precedence outranks subsequence and for German the opposite pertains. We might think therefore of a universal ranking of general ordering constraints with respect to the inflection domain and a language specific ranking of precedence and subsequence versions of them:☞The “o” used in the following constraints stands for a general ordering (either precedence or subsequence) relationship.
| [tense]oDI > [perf]oDI > [prog]oDI > [pass]oDI | universal |
| [CUI]pDI > [CUI]fDI | English |
| [CUI]fDI > [CUI]pDI | German |
Essentially the same analysis will be given for the ordering of the argument domain as for the inflection domain, though here the matter is complicated by the issue of distinguishing between arguments. How arguments are to be distinguished and what role their distinguishing features have in syntax have been the subject of a very long debate, which is still to reach its conclusion. In one view, the thematic role is the main distinguishing feature, though it is unclear still exactly what this is and therefore it is even more difficult to conclude on its role in syntax. A more recent approach has been to distinguish between arguments in terms of their involvement in event structure. As early as 1990, Grimshaw proposed that those arguments which are involved in prior events in a complex event structure occupy more prominent positions syntactically, though she coupled this requirement with a thematic hierarchy to determine the prominence of arguments associated with the same bit of event structure (1990). These days it is an optimistic hope that with a greater understanding of event structure it will be possible to do away with reference to thematic roles entirely.
Newson (2012) proposed that arguments are related to event structure by specific relating elements. These relators differ in terms of which argument they associate to which bit of the event structure. Complex events can be made up of a number of sub-events arranged in a sequence such that one sub-event precedes another. For example, a causing sub-event precedes the resulting sub-event. From this perspective we can define the different arguments by the level of the event in the event structure that they are related to. For simplicity we will refer to the argument related to the first sub-event to which an argument is related as argument 1 (Arg1) and that to the next as argument 2, etc. This means that in a transitive verb the argument related to first sub-event is Arg1 and that related to the following sub-event is Arg2. For unergatives and unaccusatives the single argument is Arg1 even though in these cases the argument is related to different parts of the event structure (the preceding one for unergatives and the following one for unaccusatives).
The ordering of the arguments in the argument domain is determined in exactly the same way as for the inflection domain: there are a set of domain precedence constraints requiring particular members of the domain to precede all others:
| [CUA]pDA | argument CU precedes argument domain |
| violated by every member of DA which precedes [CUA] |
The specific constraints require Arg1 to precede Arg2, etc., which means ranking [Arg1]pDA above [Arg2]pDA, etc. It should be obvious without demonstration how this serves to order the arguments in the relevant way.
The basic arrangement of arguments in English and German seems to be much the same, though in German this is subject to more variation due to the affects of scrambling. This clearly involves the interference of other constraints, which we will not be concerned with in the present paper. We will, however, briefly consider other argument re-ordering effects which are present in both languages in the final section of this paper.
Above it was mentioned how the root plays a linchpin role in the ordering of the argument and inflection domains within the linear string. For English the root requires a second position in the argument domain and a second to last position in the inflection domain. As was initially pointed out in Newson (2010), second and second to last positions can be achieved by the ranking of an anti-precedence (or anti-subsequence) constraint above a precedence (or subsequence) one. Anti-precedence/subsequence constraints are violated in exactly the case that the precedence/subsequence constraints are satisfied. Thus if it is important for an element not to precede a domain, but it is also important to be at the front of the same domain, the best place for it is in the second position.
The positioning of the root in English clauses can therefore be accounted for by the following constraints:
| √*pDA | root does not precede argument domain |
| violated if all members of DA follow √ | |
| √pDA | root precedes argument domain |
| violated by every member of DA that precedes √ | |
| √*fDI | root does not follow inflection domain |
| violated if all members of DI precede √ | |
| √fDI | root follows inflection domain |
| violated by every member of DI that follows √ |
With the anti-ordering constraint ranked above the ordering constraint in both cases, we will achieve the relevant position of the root with respect to each domain. However, although this ensures a certain degree of intermingling between the elements of the domains, it does not by itself guarantee the actual order, as a number of possible orderings are consistent with these rankings:
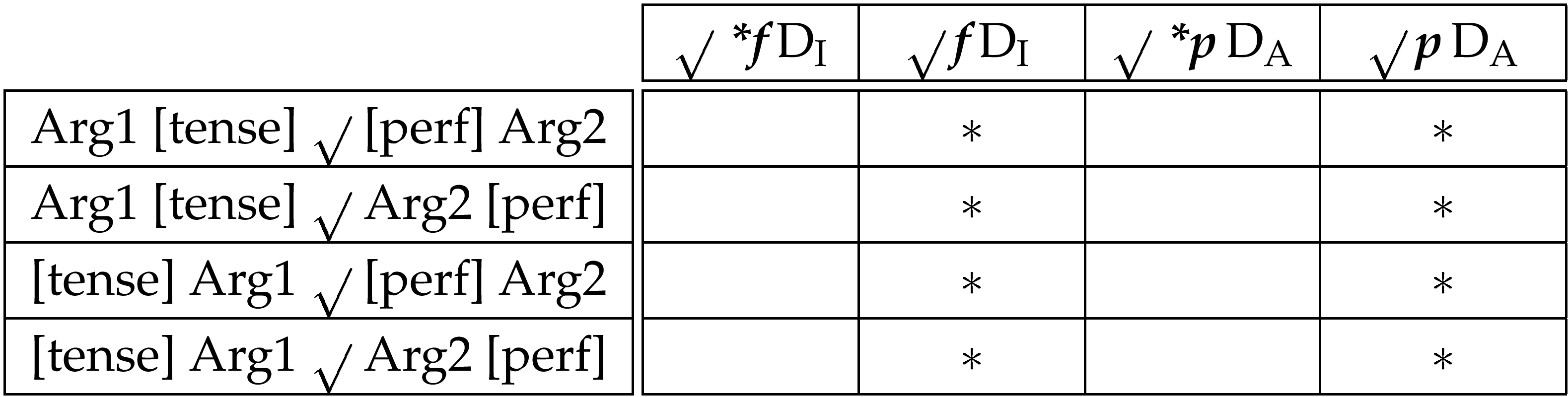
As the grammatical order of these elements involves the elements of the inflection domain being surrounded by the elements of the argument domain, we need constraints which will pull inflectional elements towards the centre. It makes sense that inflectional elements want to be near the root. If this were not the case, they would not be “inflections” as under present assumptions a bound morpheme is one for which its vocabulary realisation is restricted to the immediate context of the root. We can see then that the constraints relevant for achieving the required ordering are ones which place inflectional elements as close to the root as possible: i.e., adjacency constraints. Root adjacency is not an absolute requirement of English inflectional elements and they are realised as free morphemes (i.e., by dummy auxiliaries) under the right conditions. Thus these adjacency constraints are not so highly ranked, and come at least below the ordering constraints. The important point however, is that the root adjacency requirement for inflections is stronger than that of arguments.
It is difficult to determine the rank order of the individual adjacency constraints: is it more important for the perfect CU to be adjacent to the root than the tense CU? In fact, as the adjacency constraints are ranked below the ordering constraints, it makes no difference what the ranking of the adjacency constraints are with regard to each other. For simplicity’s sake, I will assume general alignment constraints which act as a short hand for sets of actual constraints with some internal rank ordering. These can be stated thus:
| Arga√ | argument is adjacent to root |
| violated by every element which sits between Arg and √ | |
| [infl]a√ | inflection is adjacent to root |
| violated by every element which sits between [infl] and √ |
Note that these constraints are not domain based and so consider every element in the linear string when evaluating a candidate and not just those of a particular domain.
Adding these two constraints to the evaluation in the table in (25) we see how the desired result can be achieved:
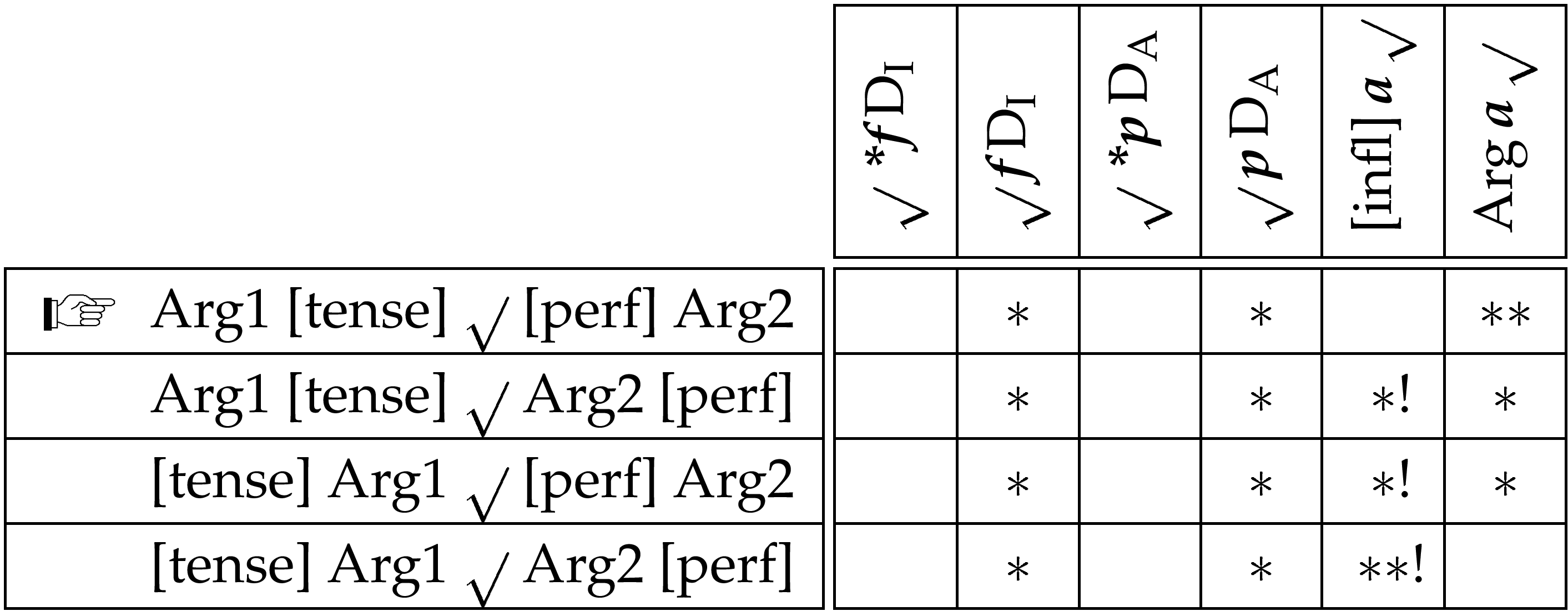
Turning to the case of German, we find a similar situation to English, but with two important differences. While the English root wants to be second in the argument domain and second to last in the inflection domain, the German root wants to be last in the argument domain and first in the inflection domain. Thus, for German the ordering constraints outrank the anti-ordering constraints:
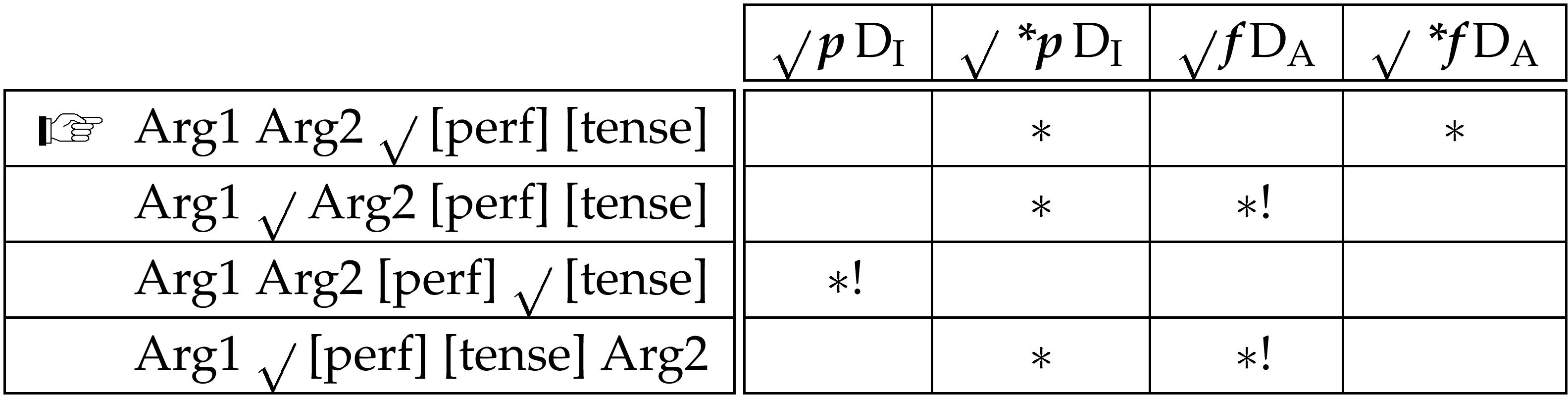
While there is only one possible optimal ordering of the argument domain elements in relation to the inflection domain elements, we will still assume that the inflection adjacency condition is the stronger because of their inflection status. As the result will be the same as in (28), there is no need to demonstrate this independently. However, this ranking will have importance in accounting for ordering effects which we will review in the next section.
So far we have looked at the basic orders of arguments and inflectional elements in the two languages. In this section we will consider some of the conditions in which these orders are changed. On the whole the main alterations to basic orders concern the order of elements of the argument domain, through “wh-fronting”, topicalisation, scrambling, etc. In this section though we will concentrate on the reordering of the inflection domain elements.
There are word order differences in both German and English between matrix and subordinate contexts, though the differences are more widespread in German. In English they are restricted to interrogative contexts, while in German they extend to all contexts. In both languages, however, they concern the tense appearing in a second position which it does not in certain subordinate contexts. In declarative contexts, this second position is defined in terms of the argument domain: this means after the first argument. For simplicity in what follows we will, adapting standard if somewhat inaccurate practice, refer to this as the V2 position. We will concentrate here on the situation in German and will briefly consider English in the next section where wh-interrogative reorderings will be briefly discussed.
It is well known that German matrix contexts demand the finite element to appear in the V2 position, a condition which is not so stringent in subordinate contexts. In particular, when a complementiser is present, the finite element stays at the end of the inflection domain, as discussed above. When the complementiser is absent, however, the subordinate finite element behaves like the matrix finite element and appears in V2 position (the following data are adapted from Ackerman & Webelhuth 1999):
| a. | Die Frau | hat | ihrem | Kind | einen | Ball | geschenkt |
| The woman | has | her-dat | child | a-acc | ball | presented | |
| ‘The woman gave her child a ball’ | |||||||
| b. | * Die Frau gestern ihrem Kind einen Ball geschenkt hat |
| a. | Ich glaube | dass | die Frau | ihrem Kind | einen Ball | geschenkt | hat |
| I think | that | the woman | her child | a ball | presented | has |
| b. | * Ich glaube dass die Frau hat ihrem Kind einen Ball geschenkt |
In (29) the matrix context is demonstrated, showing the obligatory V2 position of the finite verb. In contrast, (30) shows the obligatory final position of the finite verb in subordinate contexts introduced by a complementiser. Finally, (31) demonstrates how, in the absence of the complementiser, the finite verb is once again obligatorily V2.
The standard wisdom is that the V2 position is identified as the complementiser position and hence when this is filled, in subordinate contexts, the finite verb cannot move there. From a structural point of view, this is the most straightforward way that an interaction between the appearance of the complementiser and the position of the verb can be accounted for. Note however, that it entails the accompanying assumption that the first position is inside the CP (its specifier) and hence a movement of the element which occupies this position is obligatory in the absence of the complementiser and impossible in its presence. Thus extra assumptions are necessary to account for the supposed movements and restrictions they appear to face. An alignment account, however, is not forced to assume that because the finite verb cannot appear in V2 in the presence of a complementiser then the complementiser must occupy this position. Indeed, without making the kind of assumptions that the structural approach has to make, it would be rather difficult to claim that the complementiser is in V2 as it clearly precedes the argument domain. All that we need to claim is that the complementiser is able to satisfy the constraint which forces the finite element to occupy V2 and thereby allowing this element to occupy the final position in the inflection domain. In the following I will briefly build a theory that accomplishes this.
Let us first consider the conditions which make the finite element give up its inflection domain final position. The constraints which achieve this are specific to the tense element as no other element of the inflection domain appears in this position under any circumstance. As second position phenomena in general is achieved by ranking a domain specific anti-precedence constraint above a related precedence constraint, we might, as a first attempt, assume the following, which we refer to collectively as the V2 constraints:
| [tense]*pDA | tense does not precede argument domain |
| violated if all members of DA follow tense | |
| [tense]pDA | tense precedes argument domain |
| violated by every member of DA which precedes tense |
Unfortunately, things cannot be as simple as all this. As we know, the root wants to precede the inflection domain. But if the tense is pulled from its final position in this domain, to a position which precedes all others, then it should become the domain’s first element. In this case, what we have said so far would predict that the root should want to precede the tense in V2. The root, however, stays stubbornly in its position after the argument domain and in front of all the rest of the inflections. The exception to this is when the tense is the only element of the inflection domain. In this case both the tense and the root occupy V2:
| a. | Arg | [tense] | Arg | √ [perf] |
| John | hat | ein Buch | gelesen | |
| John | has | a book | read | |
| ‘John read a book’ | ||||
| b. | Arg | √ [tense] | Arg |
| John | liest | ein Buch | |
| John | read | a book |
It would appear that, from the perspective of the root, the tense is no longer part of the inflection domain when it is in V2 and there are other domain members present. We can achieve this state of affairs if we assume that domain membership is marked on its members and that conformity to domain based constraints is dependent on this marker. If the marker for an element is deleted, the relevant constraints will be blind to that element in the same way that domain based constraints are blind to any other non-domain member.☞In actual fact things must be a little more subtle than stated here as it is common for an element to be ordered with respect to a domain that it is not a member of — for example [tense] is ordered with respect to the argument domain. Yet clearly we would not want to have to mark these elements as domain members so that the constraints will notice them. There must therefore be a difference between constraints which order domain members with respect to the domain and those which order non-members with respect to the domain. Only the former are sensitive to the presence of the domain marker.
The deletion of the domain marker of course incurs the penalty of a faithfulness violation. But faithfulness will be violated if this enables higher ranked constraints to be satisfied. There are two conflicting requirements on the tense: it should be last in the inflection domain and it should be in V2. These two conditions cannot be satisfied at once as the inflection domain must follow the argument domain, as determined by the root’s position.☞Recall that the English situation is different as, essentially, the root occupies the V2 position and hence the whole of the inflection domain is in this position. Looked at in this way, English is more of a V2 language than German is. However, if the domain marker for the tense is deleted, the inflection domain constraint will be satisfied vacuously no matter where the tense element is placed and hence it will be free to satisfy the V2 constraints.
The only extra constraint needed to realise the above analysis is the faithfulness constraint:
With this constraint ranked lower than the argument and inflectional domain constraints, we achieve the desired result as the tense favours a second position but the root stays between the argument and inflection domains:
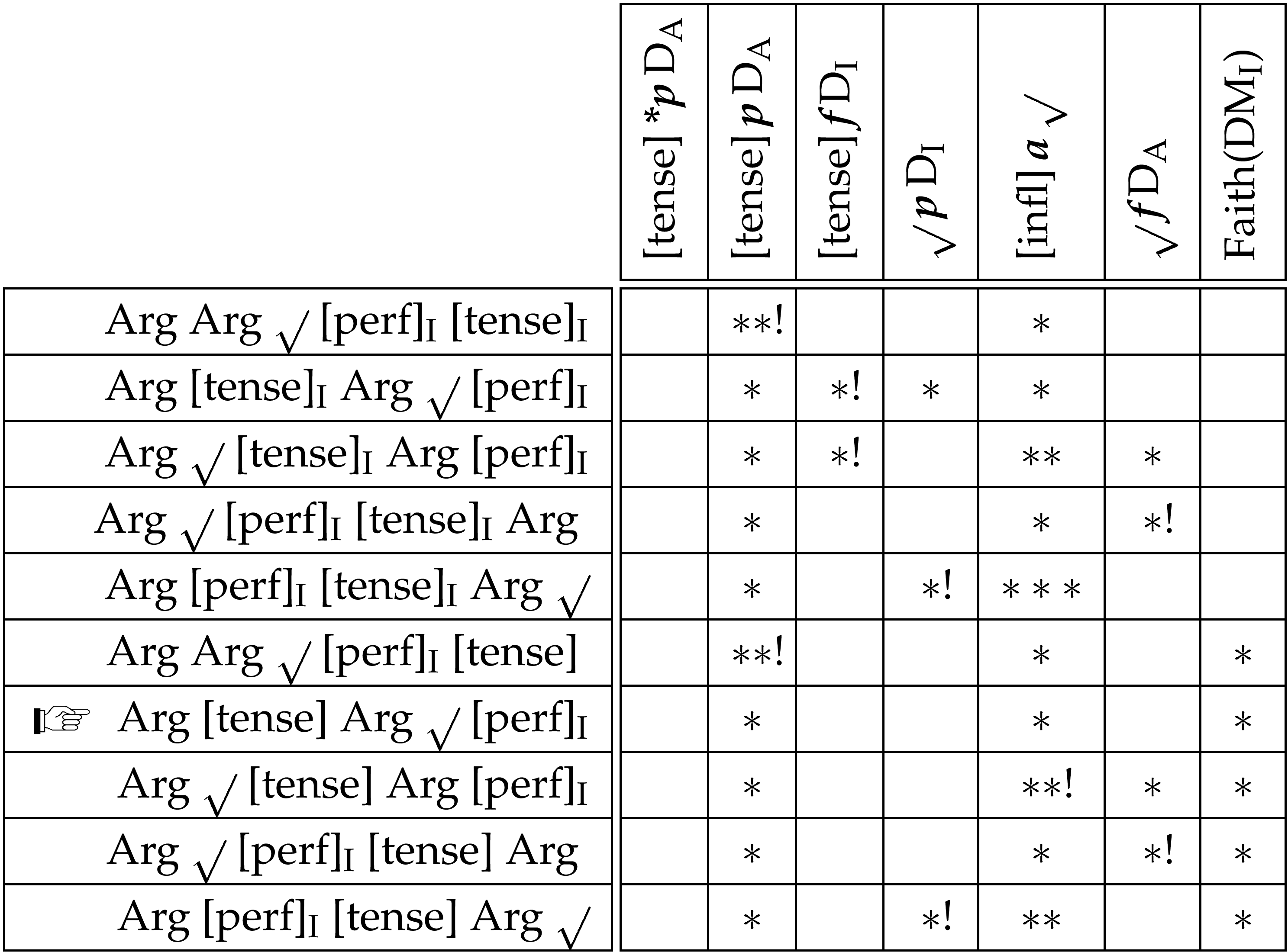
In this table, the first five candidates maintain the domain marker for the tense (indicated by an “I” index on domain members), while in the last five this is deleted on the tense. The first two constraints (V2) ensure the second position for the tense and, along with these, the next four set the conditions for the faithfulness violation. The only ways for the first three constraints to be satisfied simultaneously☞The second constraint is of course violated by every candidate considered here. Because of the high ranking anti-precedence constraint, however, this is a necessary violation. The “satisfaction” of the V2 constraints therefore involves a single violation of the second. is for either the whole of the inflection domain to appear in second position (as it does in English) or for tense to lose its domain marker and appear in the second position by itself. Given the optimal position of the root behind the argument domain and in front of the inflection domain, the second of these options is optimal. That the inflections should be adjacent to the root seems only to have a minor role in this analysis. However, it is an important condition, ensuring that the root never appears “bare”: a more important condition in German than it is in English, where inflections can escape from the root in negative and interrogative contexts. We will also see that this condition has a crucial role to play in accounting for the second position of the German root.
It remains to account for why the root abandons its argument domain final position when the tense is the only inflectional element. It turns out that we do not need to add anything more to the above to capture this fact. It is here that we see the importance of the adjacency between inflections and the root. The analysis proceeds the same as above with the exception that as the tense is the only element of the inflection domain, it can be last in this domain wherever it is situated with respect to the argument domain, thus the domain marker does not need to be deleted, see (36).
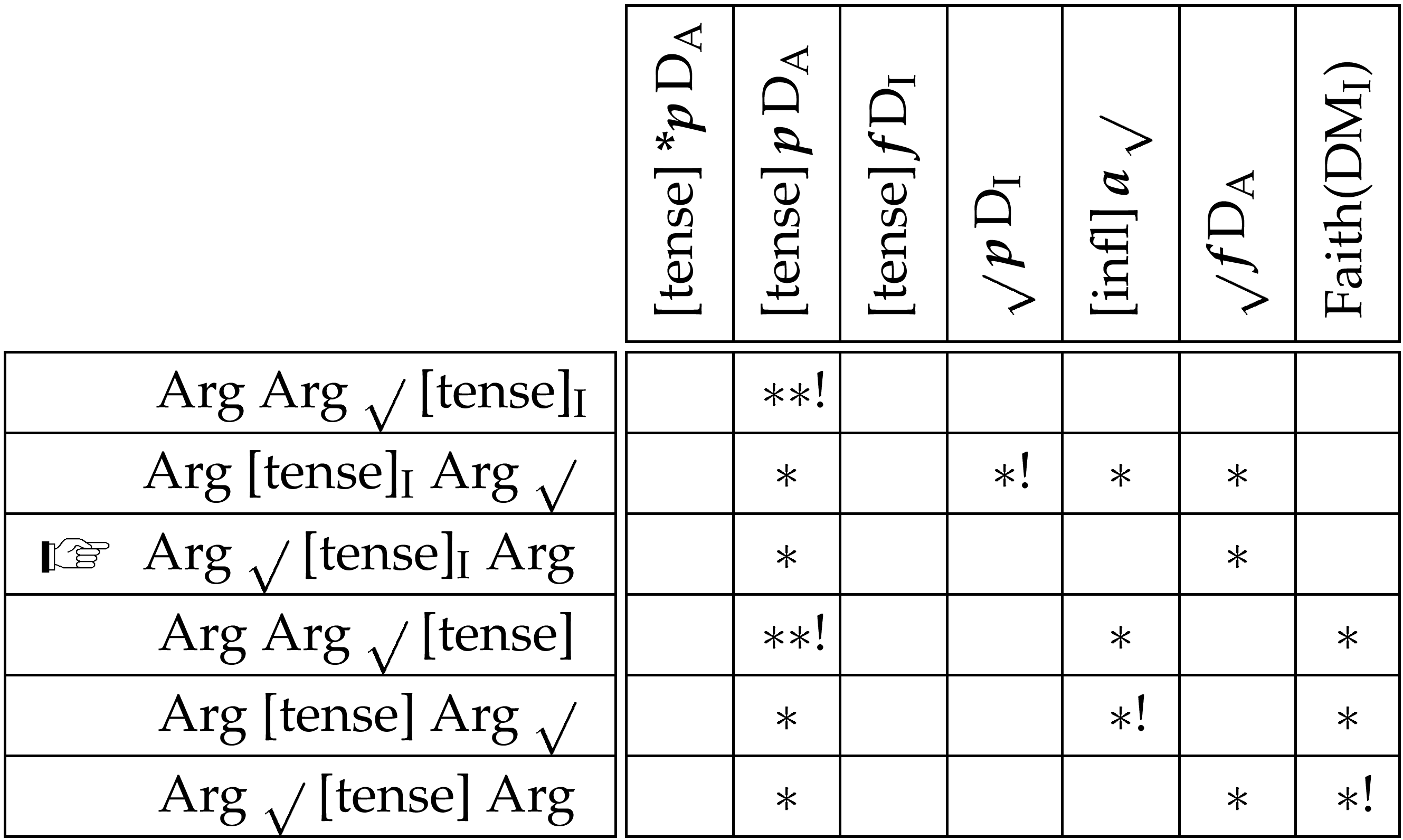
As the domain marker is undeleted, the requirement that the root be in front of this domain can only be satisfied by the root being in V2, in violation of the requirement that it follow the argument domain. Of course, it could satisfy both conditions if the tense’s domain marker were to be deleted. However, membership of the inflection domain does not affect the tense’s basic nature as an inflection and hence it is still subject to the root adjacency requirement. As this is ranked higher than the requirement that the root be behind the argument domain, the root will abandon its final position and appear with the tense in V2.
If it were less important for inflections to be adjacent to the root, the two might appear separated. This is exactly what happens in English do-support situations: the tense and the root are separated and have to be spelled out individually (see Newson & Szecsényi 2012 for the details of the auxiliary selection). Thus for English the adjacency between root and inflections is a relatively less important condition. It is essentially this property which distinguishes between “V-movement” languages such as French and German, where the root can appear fairly “high” in the argument domain, and “V-stranding” languages such as English.
Finally we turn to the role of the complementiser in determining the position of the tense in German embedded contexts. The logic of the system entails that the way that this must work is that the complementiser enables the satisfaction of the V2 constraints without the tense moving into second position. One possibility could be to make use of the fact that complementisers, besides being marked for force, are also marked for tense. However, by itself this would not solve the problem as, as we have defined the violation conditions of the constraints so far (see (32)), they will still be violated by the tense inflection when it appears in final position, no matter what else satisfies them. Instead what is needed is for the constraints to be satisfied as long as some tense element is to the front of the argument domain. This then is a requirement on the argument domain rather than the tense inflection. If we restate the constraints accordingly, we will achieve the correct result:
| DA*p[tense] | argument domain cannot be preceded by tense |
| violated if tense precedes every member of DA | |
| DAp[tense] | argument domain is preceded by tense |
| violated by every member of DA which is not preceded | |
| by tense |
These constraints will have exactly the same effect as those previously used when the tense inflection is the only tense element in the domain: the tense inflection will not be placed at the front of the argument domain, but it will be placed as near to the front as it can get — i.e., in V2. However, when there is a complementiser this can also satisfy these constraints, meaning that the tense inflection is free to stay in its inflection domain final position.
Of course, the complementiser does not satisfy the constraints in (37) in exactly the same way as the tense inflection does. The complementiser is in front of the argument domain, not in V2. Thus the anti-precedence constraint is violated while the precedence constraint is fully satisfied. This is presumably due to the effects of an even higher ranked constraint which places the complementiser at the front of the whole predicate domain:☞This may be a specific instance of a more general requirement that clause “type markers” be at the front of the predicate domain, as suggested in Newson (2000). I will not follow this up here.
| [comp]pDP | complementiser precedes predicate domain |
| violated by every member of DP which precedes [comp] |
With this constraint ranked above the V2 constraints the correct result is achieved. Note that although the high ranking anti-precedence constraint will be violated in the presence of the complementiser, nothing that the tense inflection does will make amends for this. Hence there will be no force on the tense inflection from the argument domain.
The table in (39) demonstrates the analysis.
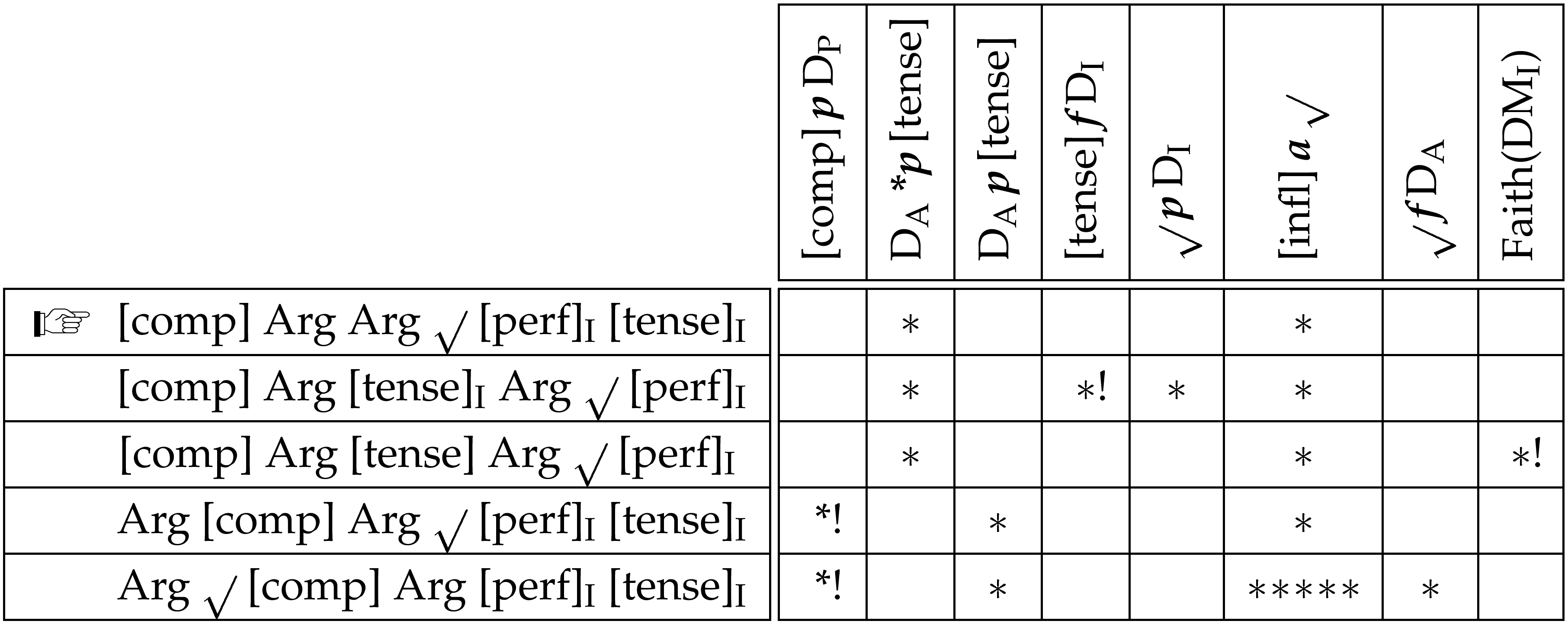
This paper could have been much longer. As it is I have decided to leave off at this point having demonstrated the general approach and gone into some of the details of the analyses that it makes possible. A fuller treatment would obviously have addressed second position phenomena in English. But this would have necessitated prior discussion of the treatment of interrogatives, a topic which itself would have doubled the paper’s length. Clearly, though, this is work that needs to be done and so I will spend a small amount of time considering the issues it gives rise to and considering possible directions analyses might go. The details will, however, be left to future work.
Wh-movement involves putting a wh-element at the front of the argument domain, disregarding its argument status or which part of event structure it is related to. Thus both object and subject wh-elements will precede the argument domain. At first this might be taken to be the result of a further argument domain ordering constraint, demanding that wh-elements precede the argument domain. Such a constraint would be disinterested in the argument/non-argument status of the wh-element, placing all wh-elements, no matter their status, at the front of the argument domain. The advantage of this approach would be that we could achieve V2 phenomena in German interrogatives in much the same way as we did above for declaratives. The reorganising of the argument domain would have little effect on the rest of the system which would work to place the tense in V2 behind whatever element is in first position, be it wh-element or subject.
Yet this cannot be the correct approach for a number of reasons. First wh-movement is not restricted to reordering a single argument domain and may involve a much wider context which includes any number of embedded predicate domains. Essentially the wh-element needs to precede the interrogative domain, which can be informally defined as coextensive with its scope.☞A formal definition of this domain would have to identify a given predicate domain as the interrogative domain based on attributed semantic properties of the predicate, similar to the treatment of an “interrogative predicate” in Newson (2000). Second, English shows a different behaviour in declarative and interrogative contexts. While the tense is in second position in both domains, the root remains in second position of the argument domain even in interrogative contexts. This means that the wh-element cannot be seen as fronting the argument domain as otherwise the root’s position would be the same in both cases. Finally when a wh-element fronts an interrogative domain, the tense that sits in the second position of this domain is that of the interrogative predicate rather than the predicate to which the wh-element is related. Thus the wh-element is clearly aligned with respect to a different and larger domain than its own argument domain.☞Whether one or more wh-elements are required to front the interrogative domain, a point of linguistic variation, rests on whether the conditions of fronting are seen as a requirement of the wh-elements themselves or of the interrogative domain, similar to the situation concerning the German argument domain being fronted by a tense element discussed above.
An issue arises concerning the status of a wh-element with regards to its own argument domain. Even if it is positioned with respect to a different domain, if it does not lose its own argument domain membership then we would expect to see consequences for elements aligned with respect to this. The evidence would suggest that while wh-subjects maintain their argument domain membership, others lose it. Thus, when a subject is fronted outside its own argument domain, the tense and root do not get positioned in second position behind the first argument of those that remain. Instead, the fronted wh-element still counts as the first element of its argument domain and tense and root follow it, albeit at a distance:
| a. | wh | ([tense] | Arg | √) | √ [tense] | Arg |
| who | did | you | think | knew | the answer |
| b. | (wh | [tense] | Arg | √) | Arg | √ | [tense] |
| * who | did | you | think | the | answer | knew |
The round brackets in the pre-vocabulary representation indicate which elements are invisible to the argument domain constraints of the subordinate predicate. As is clear, the wh-element is outside of these brackets as the subordinate tense and root are placed in second position with respect to it. However, the fronting of a non-subject does not necessarily affect the position of the tense or root of the wh-element’s predicate domain:
| a. | (wh | [tense] | Arg | √) | Arg | √ [tense] |
| what | did | you | think | he | knew |
| b. | wh | ([tense] | Arg | √) | √ [tense] | Arg |
| * what | did | you | think | knew | he |
| c. | wh | ([tense] | Arg | √) | [tense] | Arg | √ |
| * what | did | you | think | did | he | know |
In this case the wh-element is inside the brackets of invissible elements: the root and tense are in second position only by disregarding the argument status of the wh-element.
The situation is similar, though more complex, in the case where the interrogative domain coincides with the predicate domain of the wh-element. In this case, as above, the wh-subject is relevant for the positioning of both the root and the tense:
| a. | wh | √ [tense] | Arg |
| who | knew | the answer |
| b. | (wh) | Arg | √ [tense] |
| * who | the answer | knew |
| c. | wh | [tense] | Arg | √ |
| * who | did | the answer | know |
The object, however, shows a mixed influence with the tense being placed in second position following the wh-element and the root taking the subject as the first element of its relevant domain:
| a. | wh | [tense] | Arg | √ |
| what | did | he | know |
| b. | wh | √ [tense] | Arg |
| * what | knew | he | |
| wh | Arg | √ [tense] | |
| * what | he | knew |
What this suggests is that the root is aligned to the argument domain (in second position) and the wh-element loses its domain membership, but the tense is aligned to the interrogative domain (also in second position) which the wh-element is obviously part of no matter what its argument status.
The details of the analysis remain to be worked out, though I see no irresoluble problems for this. The point of this discussion, indeed the point of the whole paper, is to point out the novel approach to what are well known observations that the notion of a domain provides. Not only are the solutions that the approach provides novel, but so are many of the questions. Moreover, many of the questions and issues that arise from the structural approach do not enter into consideration from the domain approach. This demonstrates that the two approaches are entirely different, and one is not just a reworking of the other. Personally, I do not think we are yet in a position to be able to argue for one approach over the other as clearly the domain based approach is far less developed as yet and we are still discovering its properties, pitfalls and advantages. Only further development will change this and I see no reason from the present point not to continue to follow this line of investigation.
Ackerman, Farrell and Gert Webelhuth. 1999. A Lexical-Functional Analysis of Predicate Topicalization in German. American Journal of Germanic Linguistics and Literatures 11/1: 1–65.
Gáspár Miklós. 2005. Coordination in Optimality Theory. PhD. Dissertation. Eötvös Loránd University, Budapest.
Grimshaw, Jane. 1990. Argument Structure. Cambridge, MA: The MIT Press.
Koopman, Hilda and Dominique Sportiche. 1991. The position of subjects. Lingua 85: 211–258.
Larson, Richard. 1988. On the Double Object Construction. Linguistic Inquiry 19: 335–391.
Newson, Mark. 2000. The war of the left periphery. The Even Yearbook 4: 83–106.
Newson, Mark. 2010. Syntax first, words after: a possible consequence of doing Alignment Syntax without a lexicon. The Even Yearbook 9. Retrieved on 1 January 2013 from seas3.elte.hu/delg/publications/even/2010/10ne.pdf.
Newson, Mark. 2012. Perfect Have and Be. Paper presented to the Budapest Phonology Circle and Linguistics Discussion Group. 14 November 2012.
Newson, Mark and Vili Maunula. 2006. Word order in Finnish: whose side is the focus on?. The Even Yearbook 7. Retrieved on 1 January 2013 from seas3.elte.hu/delg/publications/even/2006.html#nm.
Newson, Mark and Krisztina Széchényi. 2012. Dummy Auxiliaries and Late Lexical Insertion. The Even Yearbook 10: 80–125.